C4W2P2 Keras Tutorial - The Happy House in R
Table of Contents
Important Note: This reproducible document was token from the
deeplearning.ai initiative for spreading out high quality knowledge
to world from the Coursera CEO Andrew NG. The original assignment was
answered in Python and this is my own version in R. We kept the
instructions and/or python hints in order to have the idea of the flux
in the development.
Keras tutorial - the Happy House
Welcome to the first assignment of week 2. In this assignment, you will:
- Learn to use Keras, a high-level neural networks API (programming framework), written in Python and capable of running on top of several lower-level frameworks including TensorFlow and CNTK.
- See how you can in a couple of hours build a deep learning algorithm.
Why are we using Keras? Keras was developed to enable deep learning engineers to build and experiment with different models very quickly. Just as TensorFlow is a higher-level framework than Python, Keras is an even higher-level framework and provides additional abstractions. Being able to go from idea to result with the least possible delay is key to finding good models. However, Keras is more restrictive than the lower-level frameworks, so there are some very complex models that you can implement in TensorFlow but not (without more difficulty) in Keras. That being said, Keras will work fine for many common models.
In this exercise, you'll work on the Happy House problem, which we'll explain below. Let's load the required packages and solve the problem of the Happy House!
1 Keras install
Keras is capable to use a set of different Machine Learning frameworks, in this case we are using Tensorflow for our purposes. Tensorflow is highly dependent of Python then, we need to install some packages even if we are accessing Tensorflow from R.
Assuming that we already installed tensorflow:
pip install numpy scipy pip install scikit-learn pip install pillow pip install h5py
Followed by installing keras itself:
pip install keras
That’s it! Keras is now installed on your system!
1.1 Verify that your keras.json file is configured correctly
Before we get too far we should check the contents of our keras.json
configuration file. You can find this file in $HOME/.keras/keras.json.
Installing Keras with TensorFlow backend
{
"image_dim_ordering": "tf",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Specifically, you’ll want to ensure that image_dim_ordering is set to
tf (indicating that the TensorFlow image dimension ordering is used
rather than th for Theano).
You’ll also want to ensure that the backend is properly set to tensorflow (rather than theano ). Again, both of these requirements should be satisfied by the default Keras configuration but it doesn’t hurt to double check.
Make any required updates (if any) to your configuration file and then exit your editor.
1.2 A quick note on image_dim_ordering
You might be wondering what exactly image_dim_ordering controls.
Using TensorFlow, images are represented as NumPy arrays with the
shape (height, width, depth), where the depth is the number of
channels in the image.
However, if you are using Theano, images are instead assumed to be
represented as (depth, height, width).
This little nuance is the source of a lot of headaches when using Keras (and a lot of if statments looking for these particular configurations).
If you are getting strange results when using Keras (or an error message related to the shape of a given tensor) you should:
- Check your backend.
- Ensure your image dimension ordering matches your backend.
2 Keras initialization in R
Install_And_Load <- function(Required_Packages) { Remaining_Packages <- Required_Packages[!(Required_Packages %in% installed.packages()[,"Package"])]; if(length(Remaining_Packages)) { install.packages(Remaining_Packages, repos='https://cran.rstudio.com/'); } for(package_name in Required_Packages) { library(package_name,character.only=TRUE,quietly=TRUE); } } writeLines("\n :: Install new package: keras ...") ## Specify the list of required packages to be installed and load Required_Packages <- c( "keras", "rhdf5" ) ## Call the Function Install_And_Load(Required_Packages); writeLines("\n :: Library keras loaded...")
:: Install new package: keras ... :: Library keras loaded...
Note: As you can see, we've imported a lot of functions from
Keras. You can use them easily just by calling them directly in the
notebook. Ex: X = Input(...) or X = ZeroPadding2D(...).
3 1 - The Happy House
For your next vacation, you decided to spend a week with five of your friends from school. It is a very convenient house with many things to do nearby. But the most important benefit is that everybody has commited to be happy when they are in the house. So anyone wanting to enter the house must prove their current state of happiness.

Figure 1: Figure 1 : The Happy House
As a deep learning expert, to make sure the "Happy" rule is strictly applied, you are going to build an algorithm which that uses pictures from the front door camera to check if the person is happy or not. The door should open only if the person is happy.
You have gathered pictures of your friends and yourself, taken by the front-door camera. The dataset is labeled.

Run the following code to normalize the dataset and learn about its shapes.
Load the data in R
The Hierarchical Data Format (HDF) is a set of file formats (HDF4, HDF5) designed to store and organize large amounts of data. Originally developed at the National Center for Supercomputing Applications, it is supported by The HDF Group, a non-profit corporation whose mission is to ensure continued development of HDF5 technologies and the continued accessibility of data stored in HDF. (From the Wikipedia link)
train_file <- "../data/C4P2/train_happy.h5" h5ls(train_file) train_set_x_orig <- h5read(train_file, name = "train_set_x") X_train <- aperm(train_set_x_orig, c(4, 3, 2, 1)) / 255 train_set_y_orig <- h5read(train_file, name = "train_set_y") Y_train <- train_set_y_orig dim(Y_train) <- c(length(Y_train), 1) test_file <- "../data/C4P2/test_happy.h5" h5ls(test_file) test_set_x_orig <- h5read(test_file, name = "test_set_x") X_test <- aperm(test_set_x_orig, c(4, 3, 2, 1)) / 255 test_set_y_orig <- h5read(test_file, name = "test_set_y") Y_test <- test_set_y_orig dim(Y_test) <- c(length(Y_test), 1) classes <- h5read(test_file, name = "list_classes") writeLines("\n :: X_train shape ::") dim(X_train) writeLines("\n :: Y_train shape ::") dim(Y_train) writeLines("\n :: X_test shape ::") dim(X_test) writeLines("\n :: Y_test shape ::") dim(Y_test)
group name otype dclass dim
0 / list_classes H5I_DATASET INTEGER 2
1 / train_set_x H5I_DATASET INTEGER x 600
2 / train_set_y H5I_DATASET INTEGER 600
group name otype dclass dim
0 / list_classes H5I_DATASET INTEGER 2
1 / test_set_x H5I_DATASET INTEGER x 150
2 / test_set_y H5I_DATASET INTEGER 150
:: X_train shape ::
[1] 600 64 64 3
:: Y_train shape ::
[1] 600 1
:: X_test shape ::
[1] 150 64 64 3
:: Y_test shape ::
[1] 150 1
Details of the "Happy" dataset:
- Images are of shape (64,64,3)
- Training: 600 pictures
- Test: 150 pictures
It is now time to solve the "Happy" Challenge.
4 2 - Building a model in Keras
Keras is very good for rapid prototyping. In just a short time you will be able to build a model that achieves outstanding results.
Note that Keras uses a different convention with variable names than
we've previously used with numpy and TensorFlow. In particular, rather
than creating and assigning a new variable on each step of forward
propagation such as X, Z1, A1, Z2, A2, etc. for the
computations for the different layers, in Keras code each line above
just reassigns X to a new value using X = .... In other words,
during each step of forward propagation, we are just writing the
latest value in the commputation into the same variable X. The only
exception was X_input, which we kept separate and did not overwrite,
since we needed it at the end to create the Keras model instance
(model = Model(inputs = X_input, ...) above).
Exercise: Implement a HappyModel(). This assignment is more
open-ended than most. We suggest that you start by implementing a
model using the architecture we suggest, and run through the rest of
this assignment using that as your initial model. But after that, come
back and take initiative to try out other model architectures. For
example, you might take inspiration from the model above, but then
vary the network architecture and hyperparameters however you
wish. You can also use other functions such as AveragePooling2D(),
GlobalMaxPooling2D(), Dropout().
Note: You have to be careful with your data's shapes. Use what you've learned in the videos to make sure your convolutional, pooling and fully-connected layers are adapted to the volumes you're applying it to.
Below is the example of a model in Keras in R.
## A linear stack of layers inputs <- layer_input(shape = c(64, 64, 3)) predictions <- inputs %>% layer_zero_padding_2d(padding = c(3, 3)) %>% ## Defining a 2-D convolution layer layer_conv_2d(filter=32, kernel_size=c(7, 7), padding="valid", input_shape=c(64, 64, 3) ) %>% layer_batch_normalization(axis = 3) %>% layer_activation("relu") %>% ## Defining a Pooling layer which reduces the dimentions of the ## #features map and reduces the computational complexity of the model layer_max_pooling_2d(pool_size=c(2,2)) %>% ## Flatten the input layer_flatten() %>% ## FLATTEN layer (means convert it to a vector) + FULLYCONNECTED layer_dense(units = 1, activation = "sigmoid")
You have now built a function to describe your model. To train and test this model, there are four steps in Keras:
- Create the model by calling the function above
- Compile the model by calling
model.compile(optimizer = "...", loss = "...", metrics = ["accuracy"]) - Train the model on train data by calling
model.fit(x = ..., y = ..., epochs = ..., batch_size = ...) - Test the model on test data by calling
model.evaluate(x = ..., y = ...)
If you want to know more about model.compile(), model.fit(),
model.evaluate() and their arguments, refer to the official Keras
documentation.
Exercise: Implement step 1, i.e. create the model.
Exercise: Implement step 2, i.e. compile the model to configure
the learning process. Choose the 3 arguments of compile()
wisely. Hint: the Happy Challenge is a binary classification problem.
## Model's Optimizer ## defining the type of optimizer-ADAM-Adaptive Momentum Estimation opt <- optimizer_adam(lr= 0.0001, decay = 1e-6) # lr-learning rate , # decay - learning rate decay # over each update happyModel <- keras_model(inputs = inputs, outputs = predictions) happyModel %>% compile(loss="binary_crossentropy", optimizer=opt, metrics = "accuracy" ) ## Summary of the Model and its Architecture summary(happyModel)
________________________________________________________________________________ Layer (type) Output Shape Param # ================================================================================ input_8 (InputLayer) (None, 64, 64, 3) 0 ________________________________________________________________________________ zero_padding2d_4 (ZeroPadding2D) (None, 70, 70, 3) 0 ________________________________________________________________________________ conv2d_6 (Conv2D) (None, 64, 64, 32) 4736 ________________________________________________________________________________ batch_normalization_6 (BatchNormali (None, 64, 64, 32) 128 ________________________________________________________________________________ activation_7 (Activation) (None, 64, 64, 32) 0 ________________________________________________________________________________ max_pooling2d_6 (MaxPooling2D) (None, 32, 32, 32) 0 ________________________________________________________________________________ flatten_6 (Flatten) (None, 32768) 0 ________________________________________________________________________________ dense_6 (Dense) (None, 1) 32769 ================================================================================ Total params: 37,633 Trainable params: 37,569 Non-trainable params: 64 ________________________________________________________________________________
Exercise: Implement step 3, i.e. train the model. Choose the number of epochs and the batch size.
happyModel %>% fit(X_train, Y_train, batch_size = 50, epochs=20, validation_data = list(X_test, Y_test), shuffle=TRUE, verbose = 2 )
Train on 600 samples, validate on 150 samples Epoch 1/20 - 6s - loss: 0.0726 - acc: 0.9900 - val_loss: 0.3744 - val_acc: 0.9267 Epoch 2/20 - 6s - loss: 0.0693 - acc: 0.9883 - val_loss: 0.3615 - val_acc: 0.9133 Epoch 3/20 - 6s - loss: 0.0674 - acc: 0.9850 - val_loss: 0.3727 - val_acc: 0.8733 Epoch 4/20 - 6s - loss: 0.0750 - acc: 0.9767 - val_loss: 0.3314 - val_acc: 0.9333 Epoch 5/20 - 6s - loss: 0.0663 - acc: 0.9917 - val_loss: 0.3167 - val_acc: 0.9333 Epoch 6/20 - 6s - loss: 0.0656 - acc: 0.9833 - val_loss: 0.3214 - val_acc: 0.9000 Epoch 7/20 - 6s - loss: 0.0587 - acc: 0.9867 - val_loss: 0.2997 - val_acc: 0.9267 Epoch 8/20 - 6s - loss: 0.0552 - acc: 0.9900 - val_loss: 0.2834 - val_acc: 0.9467 Epoch 9/20 - 6s - loss: 0.0527 - acc: 0.9917 - val_loss: 0.2840 - val_acc: 0.9200 Epoch 10/20 - 6s - loss: 0.0530 - acc: 0.9900 - val_loss: 0.2636 - val_acc: 0.9400 Epoch 11/20 - 6s - loss: 0.0498 - acc: 0.9917 - val_loss: 0.2512 - val_acc: 0.9400 Epoch 12/20 - 6s - loss: 0.0475 - acc: 0.9900 - val_loss: 0.2472 - val_acc: 0.9400 Epoch 13/20 - 6s - loss: 0.0449 - acc: 0.9933 - val_loss: 0.2287 - val_acc: 0.9333 Epoch 14/20 - 6s - loss: 0.0442 - acc: 0.9933 - val_loss: 0.2210 - val_acc: 0.9400 Epoch 15/20 - 6s - loss: 0.0419 - acc: 0.9933 - val_loss: 0.2095 - val_acc: 0.9400 Epoch 16/20 - 6s - loss: 0.0418 - acc: 0.9917 - val_loss: 0.1942 - val_acc: 0.9333 Epoch 17/20 - 6s - loss: 0.0410 - acc: 0.9950 - val_loss: 0.2110 - val_acc: 0.9400 Epoch 18/20 - 6s - loss: 0.0428 - acc: 0.9917 - val_loss: 0.1833 - val_acc: 0.9533 Epoch 19/20 - 6s - loss: 0.0383 - acc: 0.9933 - val_loss: 0.1700 - val_acc: 0.9467 Epoch 20/20 - 6s - loss: 0.0358 - acc: 0.9950 - val_loss: 0.1919 - val_acc: 0.9333
Note that if you run fit() again, the model will continue to train
with the parameters it has already learnt instead of reinitializing
them.
Exercise: Implement step 4, i.e. test/evaluate the model.
preds <- evaluate(happyModel, x = X_test, y = Y_test, verbose = 2 ) writeLines(paste("\n :: Loss", preds$loss, " ::", sep = " ")) writeLines(paste("\n :: Test accuracy", preds$acc, " ::", sep = " "))
:: Loss 0.191882263024648 :: :: Test accuracy 0.933333337306976 ::
If your happyModel() function worked, you should have observed much
better than random-guessing (50%) accuracy on the train and test
sets.
To give you a point of comparison, our model gets around 95% test accuracy in 40 epochs (and 99% train accuracy) with a mini batch size of 16 and adam optimizer. But our model gets decent accuracy after just 2-5 epochs, so if you're comparing different models you can also train a variety of models on just a few epochs and see how they compare.
If you have not yet achieved a very good accuracy (let's say more than 80%), here're some things you can play around with to try to achieve it:
- Try using blocks of CONV->BATCHNORM->RELU such as:
X = Conv2D(32, (3, 3), strides = (1, 1), name = 'conv0')(X)
X = BatchNormalization(axis = 3, name = 'bn0')(X)
X = Activation('relu')(X)
until your height and width dimensions are quite low and your number
of channels quite large (≈32 for example). You are encoding useful
information in a volume with a lot of channels. You can then flatten
the volume and use a fully-connected layer.
- You can use MAXPOOL after such blocks. It will help you lower the dimension in height and width.
- Change your optimizer. We find Adam works well.
- If the model is struggling to run and you get memory issues, lower your batch_size (12 is usually a good compromise)
- Run on more epochs, until you see the train accuracy plateauing.
Even if you have achieved a good accuracy, please feel free to keep playing with your model to try to get even better results.
Note: If you perform hyperparameter tuning on your model, the test set actually becomes a dev set, and your model might end up overfitting to the test (dev) set. But just for the purpose of this assignment, we won't worry about that here.
5 3 - Conclusion
Congratulations, you have solved the Happy House challenge!
Now, you just need to link this model to the front-door camera of your house. We unfortunately won't go into the details of how to do that here.
What we would like you to remember from this assignment:
- Keras is a tool we recommend for rapid prototyping. It allows you to quickly try out different model architectures. Are there any applications of deep learning to your daily life that you'd like to implement using Keras?
- Remember how to code a model in Keras and the four steps leading to the evaluation of your model on the test set. Create->Compile->Fit/Train->Evaluate/Test.
4 - Test with your own image (Optional)
Congratulations on finishing this assignment. You can now take a picture of your face and see if you could enter the Happy House. To do that:
- Click on "File" in the upper bar of this notebook, then click "Open" to go on your Coursera Hub.
- Add your image to this Jupyter Notebook's directory, in the "images" folder
- Write your image's name in the following code
- Run the code and check if the algorithm is right (0 is unhappy, 1 is happy)!
The training/test sets were quite similar; for example, all the pictures were taken against the same background (since a front door camera is always mounted in the same position). This makes the problem easier, but a model trained on this data may or may not work on your own data. But feel free to give it a try!
test_img <- image_load(path = 'assets/img/posts/p1_keras_r/SFMBOfficialSquared.jpg', grayscale = FALSE, target_size = c(64, 64) ) x <- image_to_array(test_img, data_format = "channels_last" ) d <- dim(x) imgs <- array(x, dim = c(1, d[1], d[2], d[3])) predict(happyModel, imgs, verbose = 2 )
[,1]
[1,] 1
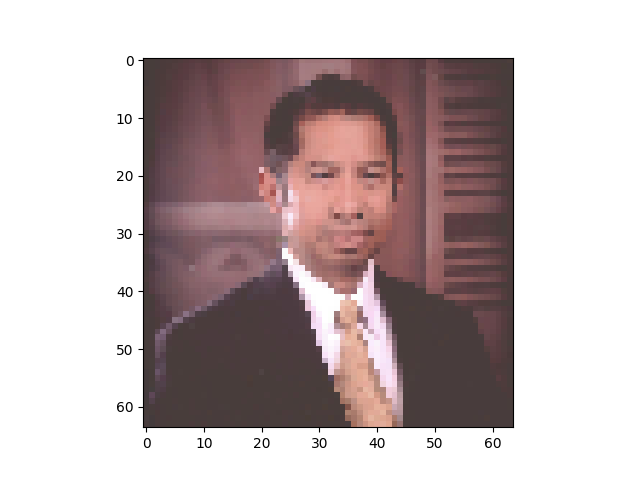
Figure 3: Testing a custom image for C4P2 CNN
6 5 - Other useful functions in Keras (Optional)
Two other basic features of Keras that you'll find useful are:
model.summary(): prints the details of your layers in a table with the sizes of its inputs/outputsplot_model(): plots your graph in a nice layout. You can even save it as.pngusingSVG()if you'd like to share it on social media ;). It is saved in "File" then "Open…" in the upper bar of the notebook.
Run the following code.
summary(happyModel)
________________________________________________________________________________ Layer (type) Output Shape Param # ================================================================================ input_8 (InputLayer) (None, 64, 64, 3) 0 ________________________________________________________________________________ zero_padding2d_4 (ZeroPadding2D) (None, 70, 70, 3) 0 ________________________________________________________________________________ conv2d_6 (Conv2D) (None, 64, 64, 32) 4736 ________________________________________________________________________________ batch_normalization_6 (BatchNormali (None, 64, 64, 32) 128 ________________________________________________________________________________ activation_7 (Activation) (None, 64, 64, 32) 0 ________________________________________________________________________________ max_pooling2d_6 (MaxPooling2D) (None, 32, 32, 32) 0 ________________________________________________________________________________ flatten_6 (Flatten) (None, 32768) 0 ________________________________________________________________________________ dense_6 (Dense) (None, 1) 32769 ================================================================================ Total params: 37,633 Trainable params: 37,569 Non-trainable params: 64 ________________________________________________________________________________
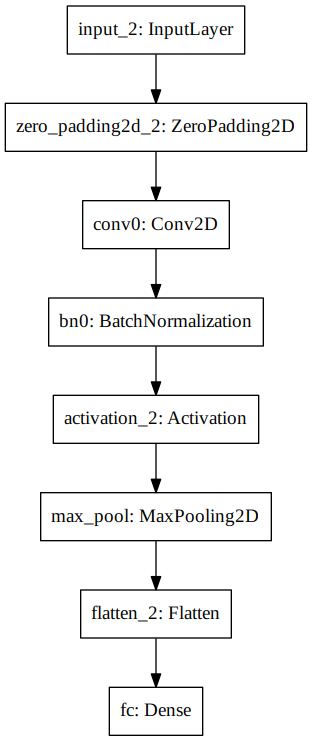
Figure 4: CNN model for the Happy House challenge
7 References
- https://towardsdatascience.com/how-to-implement-deep-learning-in-r-using-keras-and-tensorflow-82d135ae4889
- https://cambridgespark.com/content/tutorials/neural-networks-tuning-techniques/index.html
- https://keras.io/layers/normalization/#batchnormalization
- https://keras.io/layers/convolutional/#zeropadding2d
- https://keras.io/layers/convolutional/#conv2d
- https://keras.io/layers/pooling/#maxpooling2d
- https://keras.io/layers/core/#flatten
- https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
- https://github.com/pandas-dev/pandas/issues/9636
- https://keras.rstudio.com
- https://tensorflow.rstudio.com/keras/articles/examples/conv_lstm.html